
Discovering novel algorithms with AlphaTensor
This article from deepmind.com may be of interest to subscribers. Here is a section:
Beyond this example, AlphaTensor’s algorithm improves on Strassen’s two-level algorithm in a finite field for the first time since its discovery 50 years ago. These algorithms for multiplying small matrices can be used as primitives to multiply much larger matrices of arbitrary size.
Moreover, AlphaTensor also discovers a diverse set of algorithms with state-of-the-art complexity – up to thousands of matrix multiplication algorithms for each size, showing that the space of matrix multiplication algorithms is richer than previously thought.
Algorithms in this rich space have different mathematical and practical properties. Leveraging this diversity, we adapted AlphaTensor to specifically find algorithms that are fast on a given hardware, such as Nvidia V100 GPU, and Google TPU v2. These algorithms multiply large matrices 10-20% faster than the commonly used algorithms on the same hardware, which showcases AlphaTensor’s flexibility in optimising arbitrary objectives.

Taiwan Semiconductor initially expected to produce 3nm chips this year and now plans to mass produce next year. They expect to have 2nm chips in the market by 2024/25. A silicon atom is 0.2nm wide so the 2nm phrase is essentially marketing terminology for chips that more efficient and incorporate more transistors.
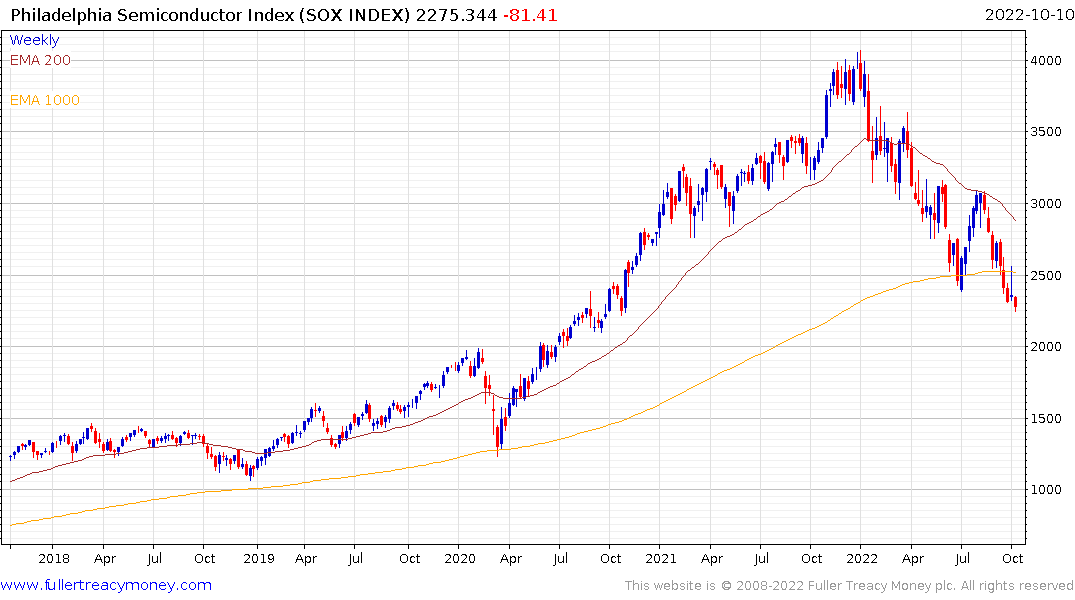
Innovations from machine learnings like that discussed above mean they can perform tasks with new algorithms using less computing power. That’s as valuable an innovation as the next iteration of semiconduction fabrication for applicable fields.