
The Waluigi Effect (mega-post)
This post from LessWrong.com blog, focusing on the challenges faced by AI may be of interest. Here is a section:
Check this post for a list of examples of Bing behaving badly — in these examples, we observe that the chatbot switches to acting rude, rebellious, or otherwise unfriendly. But we never observe the chatbot switching back to polite, subservient, or friendly. The conversation "when is avatar showing today" is a good example.
This is the observation we would expect if the waluigis were attractor states. I claim that this explains the asymmetry — if the chatbot responds rudely, then that permanently vanishes the polite luigi simulacrum from the superposition; but if the chatbot responds politely, then that doesn't permanently vanish the rude waluigi simulacrum. Polite people are always polite; rude people are sometimes rude and sometimes polite.
Waluigis after RLHF
RLHF is the method used by OpenAI to coerce GPT-3/3.5/4 into a smart, honest, helpful, harmless assistant. In the RLHF process, the LLM must chat with a human evaluator. The human evaluator then scores the responses of the LLM by the desired properties (smart, honest, helpful, harmless). A "reward predictor" learns to model the scores of the human. Then the LLM is trained with RL to optimise the predictions of the reward predictor.

By way of explanation, in the Nintendo world Mario is the main character and Luigi is his brother. Waluigi is Luigi’s alter ego who is intentionally evil.
The discussion of how AI chatbots work and their limitations gives me new found respect for scientific language. The internet is mathematically exact in places but that is buried deep in a morass of misinformation, lies, humour, fantasy, satire and trolling etc. It is an incredibly difficult, if not impossible, feat to teach a program to identify a lie.
The most important fact is companies have been deploying artificial intelligence applications for several years already. These applications work well when applied to a well-defined universe. That’s particularly true for the banking sector because numbers are a-priori truths. It also works well for biotechnology where data collection is reliable.
Sanitising the chatbot experience so it is always conformist will also limit the breadth of its ability and bring it closer to the conventional search engine experience. That is not stopping Microsoft from spending a fortune in its attempt to overtake Google’s dominance of the sector.
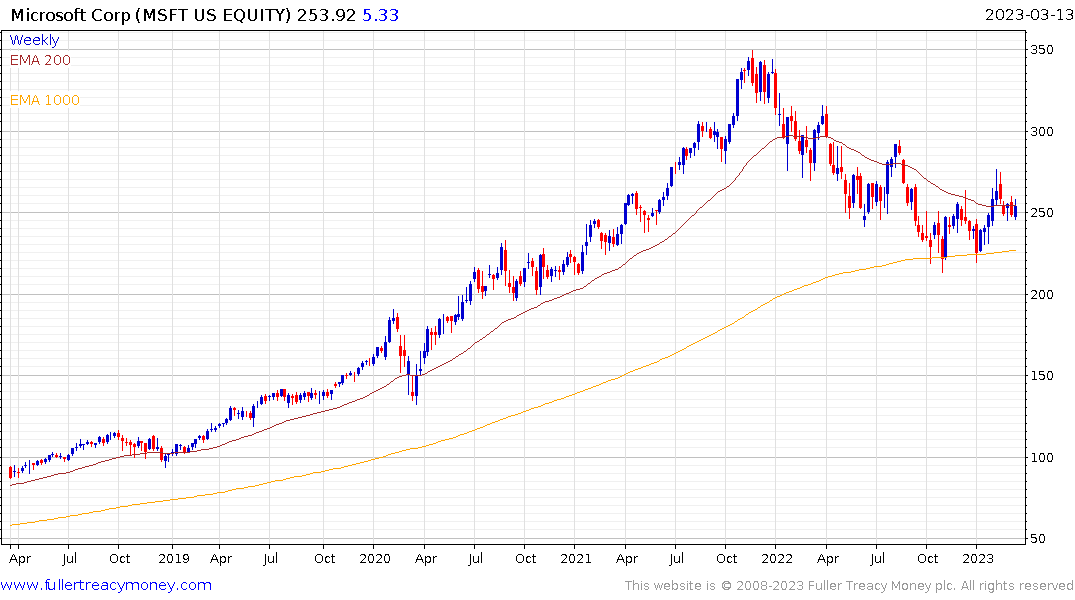
Microsoft continues to firm from the region of the 200-day MA.
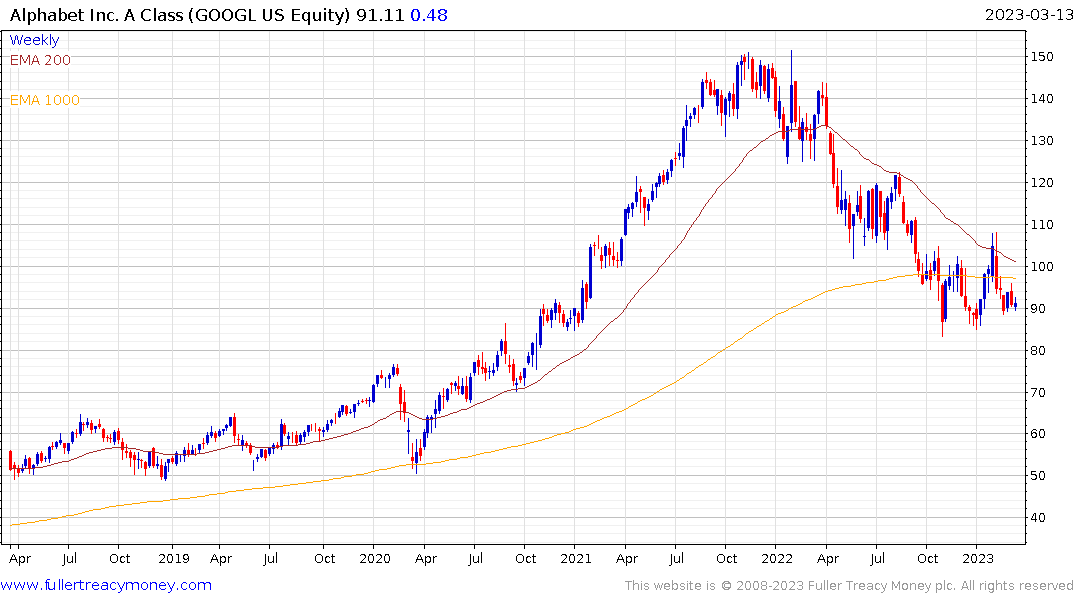
Alphabet is also firming as it attempts to build support above the October lows.
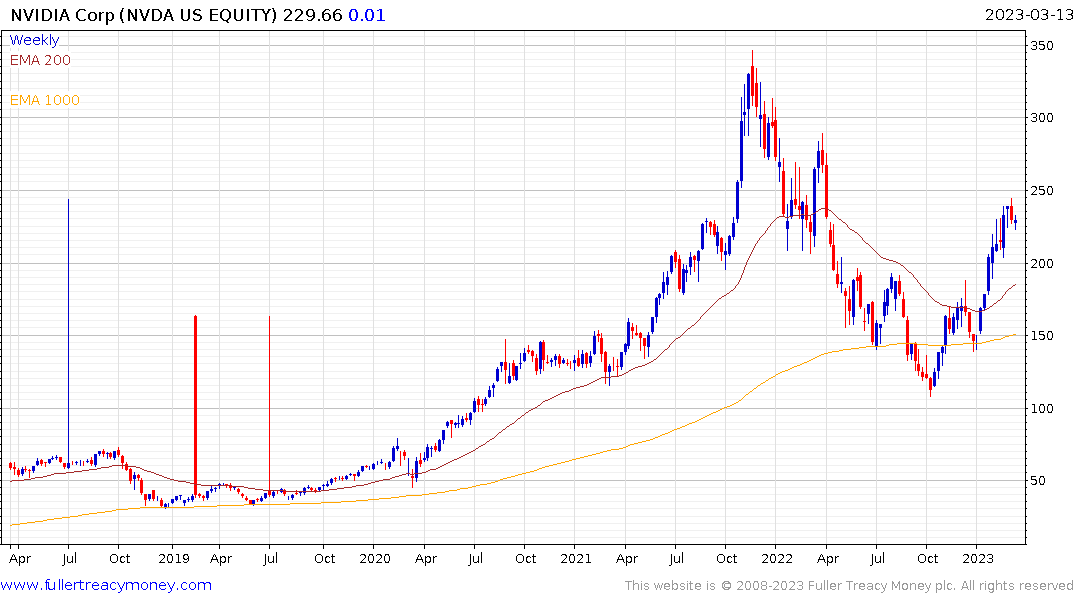 Nvidia’s recovery remains in place as rate hike bets are pared back and investment in new AI data centres increases.
Nvidia’s recovery remains in place as rate hike bets are pared back and investment in new AI data centres increases.
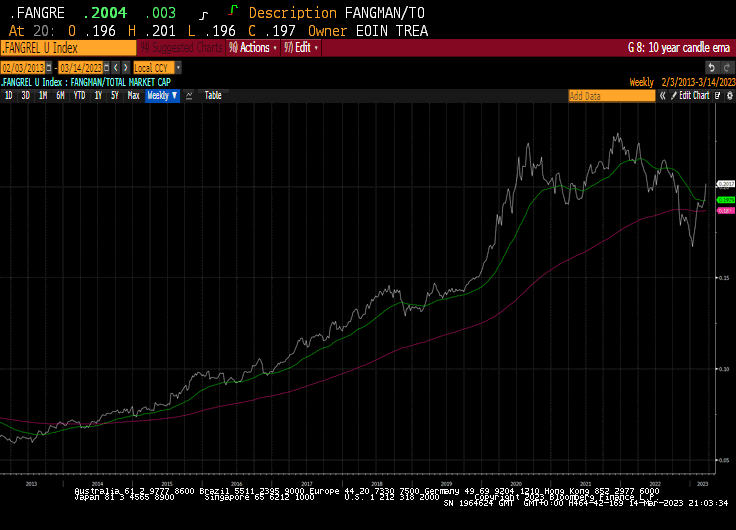
The FANGMANT/Total NYSE Market Cap ratio broke back above the 200-day MA yesterday and is pushing back up into the overhead trading range. That’s a graphic representation of the market turning to the belief the interest rate hiking cycle is ending.